
Революціонізація A/B-тестування за допомогою ШІ та Amazon Bedrock
A/B-тестування вже давно є наріжним каменем оптимізації користувацького досвіду, уточнення повідомлень та покращення потоків конверсії. Однак його традиційна залежність від випадкового призначення часто означає тривалі цикли тестування, які іноді тривають тижнями, лише для досягнення статистичної значущості. Цей процес, хоча й ефективний, за своєю суттю є повільним і часто пропускає ранні, важливі сигнали, приховані в поведінці користувачів.
Представляємо майбутнє експериментування: механізм A/B-тестування на базі ШІ, побудований за допомогою передових сервісів, таких як Amazon Bedrock, Amazon Elastic Container Service (ECS) та Amazon DynamoDB. Ця інноваційна система перевершує звичайні методи, інтелектуально аналізуючи контекст користувача для прийняття динамічних, персоналізованих рішень щодо призначення варіантів під час експерименту. Результат? Зменшення шуму, раніше виявлення значущих поведінкових патернів і значне прискорення шляху до впевнених, керованих даними висновків. Ця стаття дослідить архітектуру та методологію створення такого механізму, пропонуючи план для масштабованого, адаптивного та персоналізованого експериментування, що базується на безсерверних сервісах AWS.
Подолання обмежень традиційного A/B-тестування
Традиційне A/B-тестування працює за простим принципом: випадково призначати користувачів до різних варіантів (A або B), збирати дані та оголошувати переможця на основі заздалегідь визначених метрик. Хоча цей підхід є фундаментальним, він обтяжений невід'ємними обмеженнями, які можуть перешкоджати швидкій оптимізації та глибоким інсайтам:
- Виключно випадкове призначення: Навіть коли ранні дані натякають на значущі відмінності в уподобаннях або поведінці користувачів, традиційне A/B-тестування суворо дотримується випадкового розподілу. Це означає, що користувачі можуть бути піддані впливу субоптимальних варіантів протягом тривалих періодів, навіть якщо альтернативний варіант явно краще підходить для їхнього конкретного профілю.
- Повільна конвергенція: Необхідність збору статистично значущого обсягу даних часто означає, що експерименти затягуються на тижні. Ця затримка може уповільнити ітерації продукту, відкласти можливості отримання доходу та поставити організації у невигідне конкурентне становище.
- Високий рівень шуму: Поголівне випадкове призначення може піддавати користувачів варіантам, які явно не відповідають їхнім потребам або уподобанням. Цей "шум" може приховувати справжні інсайти, ускладнюючи розрізнення ефективних стратегій і іноді вимагаючи обширного постобробкового аналізу для сегментації даних для ясності.
- Тягар ручної оптимізації: Виявлення тонких поведінкових патернів або специфічних для сегмента уподобань зазвичай вимагає значного ручного аналізу після завершення експерименту. Цей реактивний підхід є трудомістким і часто не дозволяє ефективно використовувати сигнали в реальному часі.
Розглянемо сценарій роздрібної торгівлі: компанія тестує дві кнопки "Call-to-Action" (CTA): "Купити зараз" (Варіант A) проти "Купити зараз – Безкоштовна доставка" (Варіант B). Початкові дані можуть показувати, що Варіант B перевершує. Однак більш глибокий, ручний аналіз може виявити, що преміум-члени (які вже мають безкоштовну доставку) вагаються з Варіантом B, тоді як шукачі вигідних пропозицій кидаються до нього. Мобільні користувачі, навпаки, можуть віддати перевагу Варіанту A через розмір екрану. Традиційні методи усереднювали б ці різноманітні поведінки протягом тривалого періоду, що ускладнювало б дію на тонкі уподобання без обширної, ручної сегментації. Саме тут сила допомоги ШІ в призначенні стає безцінною, дозволяючи адаптуватися в реальному часі та досягати чудових результатів A/B-тестування.
Архітектура адаптивного механізму A/B-тестування з AWS
Адаптивний механізм A/B-тестування знаменує значну еволюцію від свого традиційного аналога. Інтегруючи контекст користувача в реальному часі та ранні поведінкові патерни, він забезпечує розумніше, динамічніше призначення варіантів. В основі цього рішення лежать інтелектуальні можливості Amazon Bedrock, який замість того, щоб призначати кожного користувача до фіксованого варіанта, оцінює індивідуальний контекст користувача, отримує історичні поведінкові дані та вибирає найбільш оптимальний варіант для цієї конкретної взаємодії.
Система побудована на надійній, безсерверній архітектурі в межах AWS, що забезпечує масштабованість, стійкість та ефективність:
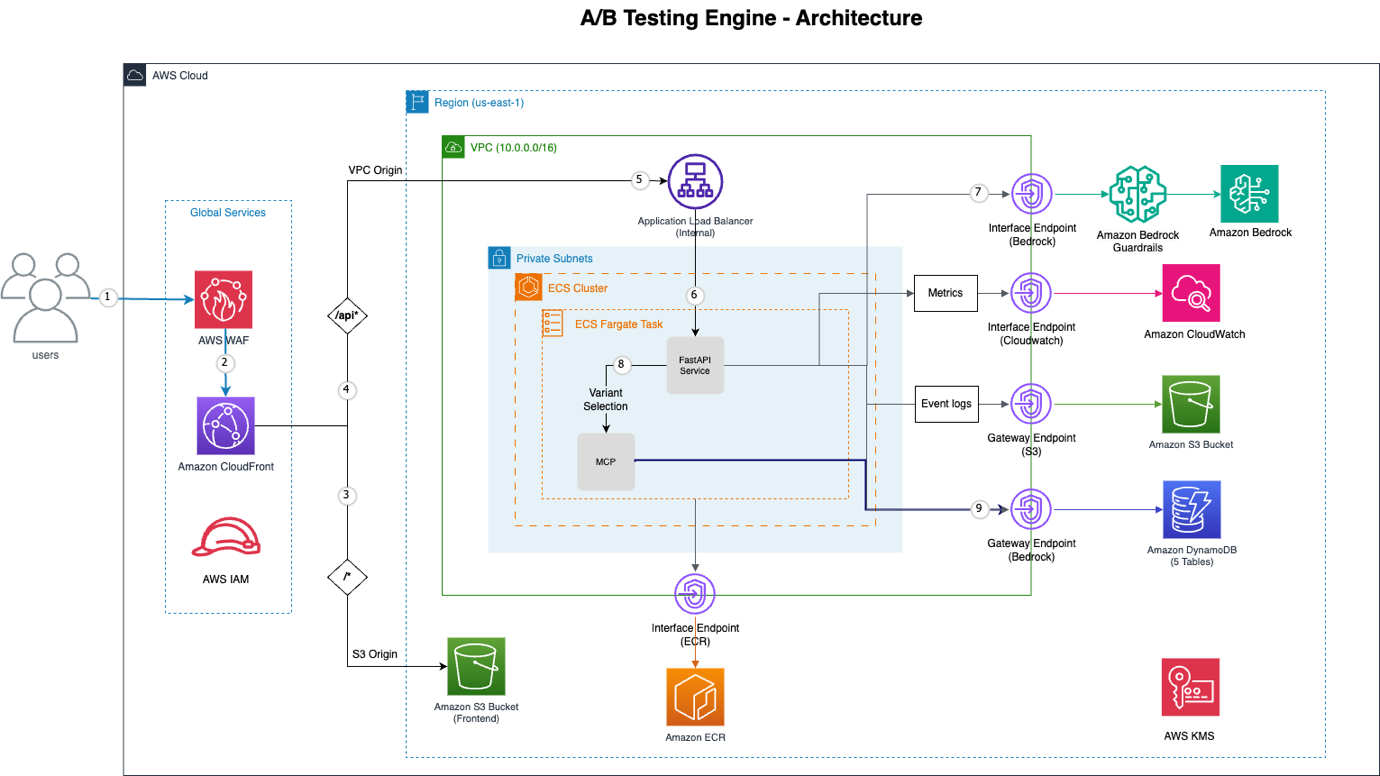
Малюнок 1: Архітектура механізму A/B-тестування
Ось розбивка ключових компонентів AWS, що роблять це можливим:
| Сервіс AWS | Функціональність |
|---|---|
| Amazon CloudFront | Глобальна мережа доставки контенту (CDN), що забезпечує захист від розподілених атак "відмова в обслуговуванні" (DDoS), запобігання SQL-ін'єкціям та обмеження швидкості. |
| AWS WAF | Брандмауер веб-додатків, інтегрований з CloudFront для підвищення безпеки. |
| VPC Origin | Встановлює приватне з'єднання від Amazon CloudFront до внутрішнього Application Load Balancer, усуваючи доступ до внутрішніх сервісів через публічний інтернет. |
| Amazon ECS with AWS Fargate | Безсерверна платформа оркестрації контейнерів, що запускає додаток FastAPI, забезпечуючи високу доступність та масштабованість без керування серверами. |
| Amazon Bedrock | Центральний двигун прийняття рішень ШІ, що використовує моделі, такі як Claude Sonnet, з нативним використанням інструментів для інтелектуального вибору варіантів. |
| Model Context Protocol (MCP) | Забезпечує структурований доступ до даних поведінки користувачів та експериментів, дозволяючи Bedrock ефективно отримувати конкретну інформацію. |
| VPC Endpoints | Забезпечує приватне з'єднання з сервісами AWS, такими як Bedrock, DynamoDB, S3, ECR та CloudWatch, підвищуючи безпеку та зменшуючи затримку. |
| Amazon DynamoDB | Повністю керована, безсерверна база даних NoSQL, що надає п'ять таблиць для експериментів, подій, призначень, профілів користувачів та пакетних завдань. |
| Amazon S3 | Використовується для розміщення статичного інтерфейсу та довготривалого зберігання журналів подій, пропонуючи високу доступність та масштабованість. |
Ця архітектура надає потужну та адаптивну платформу для експериментування, що дозволяє організаціям вийти за межі обмежень випадкового призначення та прийняти справді інтелектуальний підхід до A/B-тестування.
Роль Amazon Bedrock в інтелектуальному призначенні варіантів
Справжня інновація цього механізму A/B-тестування полягає в його здатності поєднувати кілька точок даних – контекст користувача, історичну поведінку, патерни від схожих користувачів та показники продуктивності в реальному часі – для вибору найбільш ефективного варіанта. В основі цього інтелекту лежить Amazon Bedrock, зокрема його можливості для розгортання передових генеративних моделей ШІ, таких як Claude Sonnet, з нативним використанням інструментів. Це потужне поєднання дозволяє системі імітувати експерта з A/B-тестування, приймаючи рішення в реальному часі на основі даних, які адаптуються до індивідуальної взаємодії з користувачем.
Коли користувач ініціює запит варіанта, система не просто вибирає "A" або "B". Замість цього вона створює комплексний запит, який надає Amazon Bedrock всю необхідну інформацію для прийняття обґрунтованого, оптимального рішення. Цей процес використовує здатність Bedrock інтерпретувати складні інструкції та використовувати заздалегідь визначені інструменти для збору додаткового контексту, гарантуючи, що ШІ має повну картину перед рекомендацією призначення. Для глибшого розуміння того, як такі інтелектуальні агенти оцінюються в виробництві, розгляньте такі ресурси, як Оцінка ШІ-агентів для виробництва: Практичний посібник з Strands' Evals.
Запит рішення ШІ: Контекстуальний інтелект у дії
Ефективність прийняття рішень Amazon Bedrock залежить від ретельно розробленої структури запиту, яка інформує ШІ. Цей запит складається з двох основних частин: системного запиту, що визначає роль та поведінку Bedrock, та користувацького запиту, що надає конкретні, контекстуальні дані в реальному часі для прийняття рішення. Такий дизайн гарантує, що ШІ працює в межах визначених меж, використовуючи при цьому багату, динамічну інформацію.
Ось концептуальний вигляд структури запиту, який отримує Amazon Bedrock:
# System Prompt (визначає роль та поведінку Amazon Bedrock)
system_prompt =
"""
Ви є експертом зі спеціалізації оптимізації A/B-тестування з доступом до інструментів для збору даних про поведінку користувачів.
КРИТИЧНО ВАЖЛИВІ ІНСТРУКЦІЇ:
1. ЗАВЖДИ викликайте get_user_assignment ПЕРШИМ, щоб перевірити наявні призначення
2. Викликайте інші інструменти лише тоді, якщо вам потрібна конкретна інформація для прийняття кращого рішення
3. Викликайте інструменти на основі того, яка інформація буде цінною для цього конкретного рішення
4. Якщо у користувача є існуюче призначення, збережіть його, якщо немає вагомих доказів (покращення на 30%+), щоб змінити
5. КРИТИЧНО: Ваша остаточна відповідь ПОВИННА БУТИ ТІЛЬКИ дійсним JSON без додаткового тексту, пояснень чи коментарів до або після об'єкта JSON
Доступні інструменти:
- get_user_assignment: Перевірити наявне призначення варіанта (ВИКЛИКАТИ ЦЕ ПЕРШИМ)
- get_user_profile: Отримати поведінковий профіль користувача та переваги
- get_similar_users: Знайти користувачів з подібними поведінковими патернами
- get_experiment_context: Отримати конфігурацію експерименту та продуктивність
- get_session_context: Проаналізувати поведінку поточної сесії
- get_user_journey: Отримати історію взаємодії користувача
- get_variant_performance: Отримати показники ефективності варіанта
- analyze_user_behavior: Глибокий аналіз поведінки з історії подій
- update_user_profile: Оновити профіль користувача за допомогою інсайтів, отриманих ШІ
- get_profile_learning_status: Перевірити якість даних профілю та впевненість
- batch_update_profiles: Пакетне оновлення кількох профілів користувачів
Приймайте інтелектуальні, керовані даними рішення. Використовуйте необхідні інструменти для збору достатнього контексту для оптимального вибору варіанта.
ФОРМАТ ВІДПОВІДІ: Поверніть ТІЛЬКИ об'єкт JSON. Не включайте жодного тексту до або після нього."""
# User Prompt (надає конкретний контекст рішення)
prompt = f"""Виберіть оптимальний варіант для цього користувача в експерименті {experiment_id}.
КОНТЕКСТ КОРИСТУВАЧА:
- Ідентифікатор користувача: {user_context.user_id}
- Ідентифікатор сесії: {user_context.session_id}
- Пристрій: {user_context.device_type} (Мобільний: {bool(user_context.is_mobile)})
- Поточна сторінка: {user_context.current_session.current_page}
- Реферер: {user_context.current_session.referrer_type or 'direct'}
- Попередні варіанти: {user_context.current_session.previous_variants or 'None'}
ІНСАЙТИ КОНТЕКСТУ:
{analyze_user_context()}
КОНТЕКСТ ПЕРСОНАЛІЗАЦІЇ:
- Оцінка залученості: {profile.engagement_score:.2f}
- Ймовірність конверсії: {profile.conversion_likelihood:.2f}
- Стиль взаємодії: {profile.interaction_style}
- Попередньо успішні варіанти: {
Цей всебічний запит надає Amazon Bedrock можливість діяти як інтелектуальний агент, приймаючи тонкі рішення, а не покладаючись на грубі випадкові призначення. Надаючи доступ до різних інструментів для отримання та аналізу даних, він гарантує, що модель має всю необхідну інформацію для оптимізації індивідуальних уподобань користувачів та цілей експерименту. Цей підхід значно підвищує точність та швидкість A/B-тестування, забезпечуючи більш ефективний та персоналізований користувацький досвід. Таке нативне використання інструментів є потужною функцією, схожою на концепції, досліджені в Amazon Bedrock AgentCore.
Розблокування масштабованого та персоналізованого експериментування
Інтеграція ШІ, зокрема через Amazon Bedrock, у методології A/B-тестування знаменує собою кардинальний перехід від широких, рандомізованих експериментів до точних, адаптивних та персоналізованих взаємодій. Цей механізм на базі ШІ не тільки пом'якшує обмеження традиційних підходів — такі як повільна конвергенція та високий рівень шуму — але й впроваджує неперевершені можливості для оптимізації в реальному часі. Динамічно призначаючи варіанти на основі індивідуального контексту користувача, історії поведінки та прогностичних інсайтів, організації можуть досягти швидших результатів, отримати глибші практичні дані та забезпечити справді індивідуальний користувацький досвід.
Безсерверна архітектура, що базується на сервісах AWS, таких як Amazon ECS Fargate та Amazon DynamoDB, гарантує, що ця складна система залишається масштабованою та економічно ефективною, здатною обробляти різні навантаження без ручного втручання. Цей технологічний стрибок дозволяє компаніям вийти за рамки простого визначення "переможного" варіанта для загальної аудиторії, до розуміння того, що найкраще резонує з кожним унікальним користувачем у будь-який момент часу. Майбутнє оптимізації користувацького досвіду безперечно адаптивне, інтелектуальне та працює на базі ШІ, встановлюючи новий стандарт того, як розвиваються цифрові продукти та послуги.
Першоджерело
https://aws.amazon.com/blogs/machine-learning/build-an-ai-powered-a-b-testing-engine-using-amazon-bedrock/Поширені запитання
What are the primary limitations of traditional A/B testing methods?
How does an AI-powered A/B testing engine improve upon conventional A/B testing?
Which core AWS services are utilized to build this AI-powered A/B testing engine?
What role does Amazon Bedrock play in the intelligent variant assignment process?
What is the Model Context Protocol (MCP) and its significance in this architecture?
How does the AI decision prompt structure facilitate optimal variant selection?
What are the long-term benefits of implementing AI-powered A/B testing for organizations?
Будьте в курсі
Отримуйте найсвіжіші новини ШІ на пошту.