
إحداث ثورة في اختبار أ/ب باستخدام الذكاء الاصطناعي وAmazon Bedrock
لطالما كان اختبار أ/ب حجر الزاوية في تحسين تجارب المستخدم، وصقل الرسائل، وتعزيز تدفقات التحويل. ومع ذلك، فإن اعتماده التقليدي على التعيين العشوائي غالبًا ما يعني دورات اختبار طويلة، تمتد أحيانًا لأسابيع، فقط لتحقيق دلالة إحصائية. هذه العملية، وإن كانت فعالة، بطيئة بطبيعتها وغالبًا ما تفوت الإشارات المبكرة والحاسمة الكامنة في سلوك المستخدم.
مرحباً بمستقبل التجارب: محرك اختبار أ/ب مدعوم بالذكاء الاصطناعي تم بناؤه باستخدام خدمات متطورة مثل Amazon Bedrock، وAmazon Elastic Container Service (ECS)، وAmazon DynamoDB. يتجاوز هذا النظام المبتكر الطرق التقليدية من خلال تحليل سياق المستخدم بذكاء لاتخاذ قرارات تعيين متغيرة ديناميكية وشخصية أثناء التجربة. والنتيجة؟ ضوضاء أقل، تحديد مبكر لأنماط سلوك مهمة، ومسار متسارع بشكل كبير نحو استنتاجات واثقة ومدفوعة بالبيانات. ستستكشف هذه المقالة البنية والمنهجية الكامنة وراء بناء مثل هذا المحرك، وتقدم مخططًا للتجارب القابلة للتوسع والتكيف والمخصصة والمدعومة بخدمات AWS بلا خادم.
التغلب على قيود اختبار أ/ب التقليدي
يعمل اختبار أ/ب التقليدي على مبدأ مباشر: تعيين المستخدمين عشوائيًا لمتغيرات مختلفة (أ أو ب)، وجمع البيانات، وإعلان الفائز بناءً على مقاييس محددة مسبقًا. على الرغم من أن هذا النهج أساسي، إلا أنه يعاني من قيود متأصلة يمكن أن تعيق التحسين السريع والرؤى العميقة:
- التعيين العشوائي فقط: حتى عندما تشير البيانات المبكرة إلى اختلافات ذات مغزى في تفضيلات المستخدم أو سلوكياته، يلتزم اختبار أ/ب التقليدي بشكل صارم بالتوزيع العشوائي. هذا يعني أن المستخدمين قد يتعرضون لمتغيرات دون المستوى الأمثل لفترات طويلة، حتى لو كان بديل معين يؤدي بشكل أفضل لملفهم الشخصي المحدد.
- التقارب البطيء: غالبًا ما تتطلب ضرورة جمع حجم كبير من البيانات ذو دلالة إحصائية أن تستمر التجارب لأسابيع. يمكن أن يؤدي هذا التأخير إلى إبطاء تكرارات المنتج، وتأجيل فرص الإيرادات، ووضع المنظمات في وضع تنافسي غير مواتٍ.
- مستوى ضوضاء عالٍ: يمكن أن يؤدي التعيين العشوائي الشامل إلى تعريض المستخدمين لمتغيرات لا تتوافق بوضوح مع احتياجاتهم أو تفضيلاتهم. يمكن أن تحجب هذه "الضوضاء" رؤى حقيقية، مما يجعل من الصعب تمييز الاستراتيجيات الفعالة ويتطلب أحيانًا تحليلًا لاحقًا مكثفًا لتجزئة البيانات من أجل الوضوح.
- عبء التحسين اليدوي: يتطلب تحديد أنماط السلوك الدقيقة أو التفضيلات الخاصة بالقطاعات عادةً تحليلًا يدويًا كبيرًا بعد انتهاء التجربة. هذا النهج التفاعلي يستغرق وقتًا طويلاً وغالبًا ما يفشل في الاستفادة من الإشارات في الوقت الفعلي بفعالية.
لنتخيل سيناريو في قطاع التجزئة: شركة تختبر زرين لدعوة العمل (CTA): "اشترِ الآن" (المتغير أ) مقابل "اشترِ الآن – شحن مجاني" (المتغير ب). قد تظهر البيانات الأولية أن المتغير ب يتفوق في الأداء. ومع ذلك، يمكن أن يكشف تحليل يدوي أعمق أن الأعضاء المميزين (الذين لديهم شحن مجاني بالفعل) يترددون مع المتغير ب، بينما يتدفق الباحثون عن الصفقات إليه. مستخدمو الجوال، على العكس، قد يفضلون المتغير أ بسبب حجم الشاشة. ستقوم الطرق التقليدية بمتوسط هذه السلوكيات المتنوعة على مدى فترة طويلة، مما يجعل من الصعب التصرف بناءً على التفضيلات الدقيقة دون تجزئة يدوية مكثفة. وهذا هو بالضبط حيث تصبح قوة التعيين بمساعدة الذكاء الاصطناعي لا تقدر بثمن، مما يسمح بالتكيف في الوقت الفعلي ونتائج اختبار أ/ب المتفوقة.
تصميم محرك اختبار أ/ب تكيفي باستخدام AWS
يمثل محرك اختبار أ/ب التكيفي تطورًا مهمًا عن نظيره التقليدي. من خلال دمج سياق المستخدم في الوقت الفعلي وأنماط السلوك المبكرة، فإنه يمكّن من تعيينات متغيرة أكثر ذكاءً وديناميكية. في جوهره، يستفيد هذا الحل من القدرات الذكية لـ Amazon Bedrock، والذي، بدلاً من إلزام كل مستخدم بمتغير ثابت، يقوم بتقييم سياق المستخدم الفردي، واسترداد البيانات السلوكية التاريخية، واختيار المتغير الأمثل لهذا التفاعل المحدد.
تم بناء النظام على بنية قوية بلا خادم داخل AWS، مما يضمن قابلية التوسع والمرونة والكفاءة:
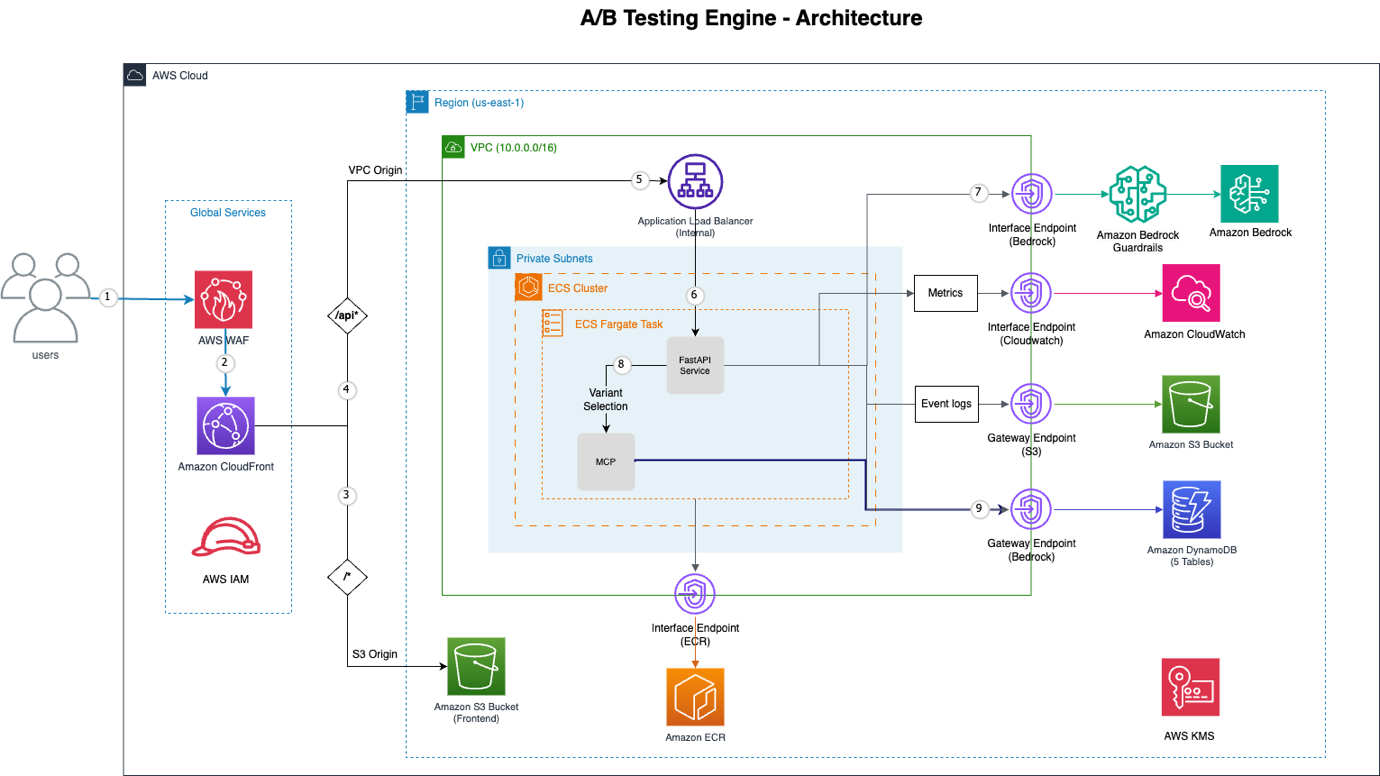
الشكل 1: بنية محرك اختبار أ/ب
فيما يلي تفصيل للمكونات الرئيسية لـ AWS التي تجعل هذا ممكنًا:
| خدمة AWS | الوظائف |
|---|---|
| Amazon CloudFront | شبكة توصيل محتوى عالمية (CDN) توفر حماية من هجمات الحرمان من الخدمة الموزعة (DDoS)، وردع حقن SQL، وتحديد المعدل. |
| AWS WAF | جدار حماية لتطبيقات الويب (Web Application Firewall) مدمج مع CloudFront لتعزيز الأمان. |
| VPC Origin | ينشئ اتصالاً خاصًا من Amazon CloudFront إلى Application Load Balancer داخلي، مما يلغي التعرض العام لخدمات الواجهة الخلفية عبر الإنترنت. |
| Amazon ECS with AWS Fargate | منصة تنسيق حاويات بلا خادم تشغل تطبيق FastAPI، مما يضمن التوفر العالي وقابلية التوسع دون الحاجة إلى إدارة الخوادم. |
| Amazon Bedrock | محرك قرار الذكاء الاصطناعي المركزي، يستخدم نماذج مثل Claude Sonnet مع استخدام الأدوات الأصلية لاختيار المتغيرات الذكي. |
| بروتوكول سياق النموذج (MCP) | يوفر وصولاً منظمًا لسلوك المستخدم وبيانات التجربة، مما يمكّن Bedrock من استرداد معلومات محددة بكفاءة. |
| نقاط نهاية VPC (VPC Endpoints) | يضمن اتصالاً خاصًا بخدمات AWS مثل Bedrock وDynamoDB وS3 وECR وCloudWatch، مما يعزز الأمان ويقلل من زمن الانتقال. |
| Amazon DynamoDB | قاعدة بيانات NoSQL مُدارة بالكامل وبلا خادم توفر خمسة جداول للتجارب والأحداث والتعيينات وملفات تعريف المستخدمين والمهام المجمعة. |
| Amazon S3 | يُستخدم لاستضافة الواجهة الأمامية الثابتة والتخزين الدائم لسجلات الأحداث، مما يوفر توفرًا عاليًا وقابلية للتوسع. |
توفر هذه البنية منصة تجريب قوية وتكيفية، تمكن المؤسسات من تجاوز قيود التعيين العشوائي وتبني نهج ذكي حقًا لاختبار أ/ب.
دور Amazon Bedrock في التعيين الذكي للمتغيرات
يكمن الابتكار الحقيقي لمحرك اختبار أ/ب هذا في قدرته على الجمع بين نقاط بيانات متعددة – سياق المستخدم، والسلوك التاريخي، والأنماط من المستخدمين المشابهين، ومقاييس الأداء في الوقت الفعلي – لاختيار المتغير الأكثر فعالية. وفي صميم هذا الذكاء يقع Amazon Bedrock، وبشكل خاص قدراته على نشر نماذج الذكاء الاصطناعي التوليدي المتقدمة مثل Claude Sonnet مع استخدام الأدوات الأصلية. يتيح هذا الدمج القوي للنظام محاكاة أخصائي اختبار أ/ب خبير، واتخاذ قرارات في الوقت الفعلي ومدفوعة بالبيانات تتكيف مع تفاعلات المستخدم الفردية.
عندما يبدأ المستخدم طلب متغير، لا يقوم النظام ببساطة باختيار "أ" أو "ب". بدلاً من ذلك، يقوم بإنشاء مطالبة شاملة تزود Amazon Bedrock بجميع المعلومات الضرورية لاتخاذ قرار مستنير ومثالي. تستفيد هذه العملية من قدرة Bedrock على تفسير التعليمات المعقدة واستخدام الأدوات المحددة مسبقًا لجمع سياق إضافي، مما يضمن أن الذكاء الاصطناعي لديه الصورة الكاملة قبل التوصية بالتعيين. لفهم أعمق لكيفية تقييم مثل هذه العوامل الذكية في الإنتاج، فكر في استكشاف موارد مثل تقييم وكلاء الذكاء الاصطناعي للإنتاج: دليل عملي لتقييمات Strands.
مطالبة قرار الذكاء الاصطناعي: الذكاء السياقي في العمل
تعتمد فعالية اتخاذ القرار في Amazon Bedrock على بنية المطالبة المصممة بدقة والتي تزود الذكاء الاصطناعي بالمعلومات. تتكون هذه المطالبة من جزأين رئيسيين: مطالبة نظام تحدد دور وسلوك Bedrock، ومطالبة مستخدم توفر بيانات سياقية محددة وفي الوقت الفعلي للقرار. يضمن هذا التصميم أن يعمل الذكاء الاصطناعي ضمن حدود محددة بينما يستفيد من معلومات غنية وديناميكية.
فيما يلي نظرة مفاهيمية على بنية المطالبة التي يتلقاها Amazon Bedrock:
# مطالبة النظام (تحدد دور وسلوك Amazon Bedrock)
system_prompt =
"""
أنت أخصائي تحسين اختبار أ/ب خبير ولديك إمكانية الوصول إلى أدوات لجمع بيانات سلوك المستخدم.
تعليمات هامة:
1. قم دائمًا باستدعاء get_user_assignment أولاً للتحقق من التعيينات الحالية
2. استدعِ الأدوات الأخرى فقط إذا كنت بحاجة إلى معلومات محددة لاتخاذ قرار أفضل
3. استدعِ الأدوات بناءً على المعلومات التي ستكون قيمة لهذا القرار المحدد
4. إذا كان لدى المستخدم تعيين موجود، فاحتفظ به ما لم يكن هناك دليل قوي (تحسين بنسبة 30%+) لتغييره
5. هام للغاية: يجب أن تكون استجابتك النهائية عبارة عن كائن JSON صالح فقط بدون أي نص إضافي أو تفسيرات أو تعليقات قبل أو بعد كائن JSON
الأدوات المتاحة:
- get_user_assignment: التحقق من تعيين المتغير الحالي (استدعِ هذا أولاً)
- get_user_profile: الحصول على ملف تعريف المستخدم السلوكي وتفضيلاته
- get_similar_users: البحث عن المستخدمين ذوي أنماط السلوك المماثلة
- get_experiment_context: الحصول على تكوين وأداء التجربة
- get_session_context: تحليل سلوك الجلسة الحالية
- get_user_journey: الحصول على سجل تفاعلات المستخدم
- get_variant_performance: الحصول على مقاييس أداء المتغيرات
- analyze_user_behavior: تحليل سلوكي عميق من سجل الأحداث
- update_user_profile: تحديث ملف تعريف المستخدم برؤى مستنبطة من الذكاء الاصطناعي
- get_profile_learning_status: التحقق من جودة بيانات الملف الشخصي والثقة
- batch_update_profiles: تحديث ملفات تعريف متعددة دفعة واحدة
اتخذ قرارات ذكية ومدفوعة بالبيانات. استخدم الأدوات التي تحتاجها لجمع سياق كافٍ لاختيار المتغير الأمثل.
تنسيق الاستجابة: أعد كائن JSON فقط. لا تقم بتضمين أي نص قبله أو بعده."""
# مطالبة المستخدم (توفر سياق قرار محدد)
prompt = f"""اختر المتغير الأمثل لهذا المستخدم في التجربة {experiment_id}.
سياق المستخدم:
- معرف المستخدم: {user_context.user_id}
- معرف الجلسة: {user_context.session_id}
- الجهاز: {user_context.device_type} (الجوال: {bool(user_context.is_mobile)})
- الصفحة الحالية: {user_context.current_session.current_page}
- المصدر: {user_context.current_session.referrer_type or 'direct'}
- المتغيرات السابقة: {user_context.current_session.previous_variants or 'None'}
رؤى السياق:
{analyze_user_context()}
سياق التخصيص:
- درجة التفاعل: {profile.engagement_score:.2f}
- احتمالية التحويل: {profile.conversion_likelihood:.2f}
- نمط التفاعل: {profile.interaction_style}
- المتغيرات الناجحة سابقًا: {
تمكّن هذه المطالبة الشاملة Amazon Bedrock من العمل كوكيل ذكي، يتخذ قرارات دقيقة بدلاً من الاعتماد على التعيينات العشوائية الخام. من خلال توفير الوصول إلى أدوات مختلفة لاسترداد البيانات وتحليلها، فإنها تضمن أن النموذج يمتلك جميع المعلومات الضرورية للتحسين وفقًا لتفضيلات المستخدم الفردية وأهداف التجربة. يعزز هذا النهج بشكل كبير دقة وسرعة اختبار أ/ب، مما يؤدي إلى تجارب مستخدم أكثر فعالية وتخصيصًا. يعد استخدام الأدوات الأصلية هذا ميزة قوية، مشابهة للمفاهيم المستكشفة في Amazon Bedrock AgentCore.
فتح آفاق التجارب القابلة للتوسع والمخصصة
يمثل دمج الذكاء الاصطناعي، وخاصةً من خلال Amazon Bedrock، في منهجيات اختبار أ/ب تحولًا محوريًا من التجارب الواسعة والعشوائية إلى تفاعلات دقيقة وتكيفية ومخصصة. لا يخفف محرك الذكاء الاصطناعي هذا من قيود الأساليب التقليدية — مثل التقارب البطيء والضوضاء العالية — فحسب، بل يقدم أيضًا قدرات لا مثيل لها للتحسين في الوقت الفعلي. من خلال تعيين المتغيرات ديناميكيًا بناءً على سياق المستخدم الفردي، والسلوك التاريخي، والرؤى التنبؤية، يمكن للمؤسسات تحقيق نتائج أسرع، واستخلاص ذكاء عملي أعمق، وتقديم تجارب مستخدم مصممة خصيصًا.
تضمن البنية بلا خادم المدعومة بخدمات AWS مثل Amazon ECS Fargate وAmazon DynamoDB أن يظل هذا النظام المتطور قابلاً للتوسع وفعالاً من حيث التكلفة، وقادرًا على التعامل مع أحمال مختلفة دون تدخل يدوي. يتيح هذا التطور التكنولوجي للشركات تجاوز مجرد تحديد متغير "فائز" لجمهور عام، نحو فهم ما يلقى صدى أفضل لدى كل مستخدم فريد في أي لحظة معينة. إن مستقبل تحسين تجربة المستخدم هو بلا شك تكيفي وذكي ومدعوم بالذكاء الاصطناعي، مما يضع معيارًا جديدًا لكيفية تطور المنتجات والخدمات الرقمية.
المصدر الأصلي
https://aws.amazon.com/blogs/machine-learning/build-an-ai-powered-a-b-testing-engine-using-amazon-bedrock/الأسئلة الشائعة
What are the primary limitations of traditional A/B testing methods?
How does an AI-powered A/B testing engine improve upon conventional A/B testing?
Which core AWS services are utilized to build this AI-powered A/B testing engine?
What role does Amazon Bedrock play in the intelligent variant assignment process?
What is the Model Context Protocol (MCP) and its significance in this architecture?
How does the AI decision prompt structure facilitate optimal variant selection?
What are the long-term benefits of implementing AI-powered A/B testing for organizations?
ابقَ على اطلاع
احصل على آخر أخبار الذكاء الاصطناعي في بريدك.