
Революционизиране на A/B тестването с изкуствен интелект и Amazon Bedrock
A/B тестването отдавна е крайъгълен камък за оптимизиране на потребителското изживяване, прецизиране на съобщенията и подобряване на потоците за конверсия. И все пак, традиционното му разчитане на произволно присвояване често означава продължителни цикли на тестване, понякога обхващащи седмици, само за да се постигне статистическа значимост. Този процес, макар и ефективен, е по своята същност бавен и често пропуска ранни, решаващи сигнали, скрити в поведението на потребителите.
Навлезте в бъдещето на експериментирането: механизъм за A/B тестване, задвижван от изкуствен интелект, изграден с помощта на авангардни услуги като Amazon Bedrock, Amazon Elastic Container Service (ECS) и Amazon DynamoDB. Тази иновативна система надхвърля конвенционалните методи, като интелигентно анализира потребителския контекст, за да взема динамични, персонализирани решения за присвояване на варианти по време на експеримент. Резултатът? Намален шум, по-ранно идентифициране на значими поведенчески модели и драстично ускорен път към уверени, базирани на данни заключения. Тази статия ще разгледа архитектурата и методологията зад изграждането на такъв механизъм, предлагайки план за мащабируемо, адаптивно и персонализирано експериментиране, задвижвано от безсървърни AWS услуги.
Преодоляване на ограниченията на традиционното A/B тестване
Традиционното A/B тестване работи на прост принцип: произволно присвояване на потребители към различни варианти (A или B), събиране на данни и обявяване на победител въз основа на предварително дефинирани показатели. Макар и основополагащ, този подход е изпълнен с присъщи ограничения, които могат да попречат на бързата оптимизация и задълбочените прозрения:
- Изцяло произволно присвояване: Дори когато ранните данни подсказват значими разлики в потребителските предпочитания или поведения, традиционното A/B тестване стриктно се придържа към произволно разпределение. Това означава, че потребителите могат да бъдат изложени на по-малко оптимални варианти за продължителни периоди, дори ако алтернатива очевидно се представя по-добре за техния специфичен профил.
- Бавна конвергенция: Необходимостта от събиране на статистически значим обем данни често означава, че експериментите се проточват със седмици. Това забавяне може да забави итерациите на продуктите, да отложи възможностите за приходи и да постави организациите в конкурентно неизгодно положение.
- Високо ниво на шум: Общото произволно присвояване може да изложи потребителите на варианти, които ясно не съответстват на техните нужди или предпочитания. Този „шум“ може да замъгли истинските прозрения, което затруднява разпознаването на ефективни стратегии и понякога изисква обширен пост-хок анализ за сегментиране на данните за по-голяма яснота.
- Натоварване с ръчна оптимизация: Идентифицирането на нюансирани поведенчески модели или специфични за сегмента предпочитания обикновено изисква значителен ръчен анализ след приключване на експеримента. Този реактивен подход отнема време и често не успява ефективно да използва сигналите в реално време.
Разгледайте сценарий в търговията на дребно: компания тества два бутона за призив към действие (CTA): „Купи сега“ (Вариант А) срещу „Купи сега – Безплатна доставка“ (Вариант Б). Първоначалните данни може да показват, че Вариант Б се представя по-добре. Въпреки това, по-задълбочен, ръчен анализ може да разкрие, че премиум членовете (които вече имат безплатна доставка) се колебаят с Вариант Б, докато търсещите сделки се стичат към него. Мобилните потребители, обратно, може да предпочетат Вариант А поради размера на екрана. Традиционните методи биха осреднили тези разнообразни поведения за дълъг период, което затруднява действието въз основа на нюансирани предпочитания без обширна, ръчна сегментация. Именно тук силата на подпомогнатото от AI присвояване става безценна, позволявайки адаптация в реално време и превъзходни резултати от A/B тестването.
Архитектура на адаптивен механизъм за A/B тестване с AWS
Адаптивният механизъм за A/B тестване бележи значителна еволюция от традиционния си аналог. Чрез интегриране на потребителски контекст в реално време и ранни поведенчески модели, той позволява по-интелигентни, по-динамични присвоявания на варианти. В основата си, това решение използва интелигентните възможности на Amazon Bedrock, който, вместо да ангажира всеки потребител с фиксиран вариант, оценява индивидуалния потребителски контекст, извлича исторически поведенчески данни и избира най-оптималния вариант за това конкретно взаимодействие.
Системата е изградена върху стабилна, безсървърна архитектура в рамките на AWS, осигуряваща мащабируемост, устойчивост и ефективност:
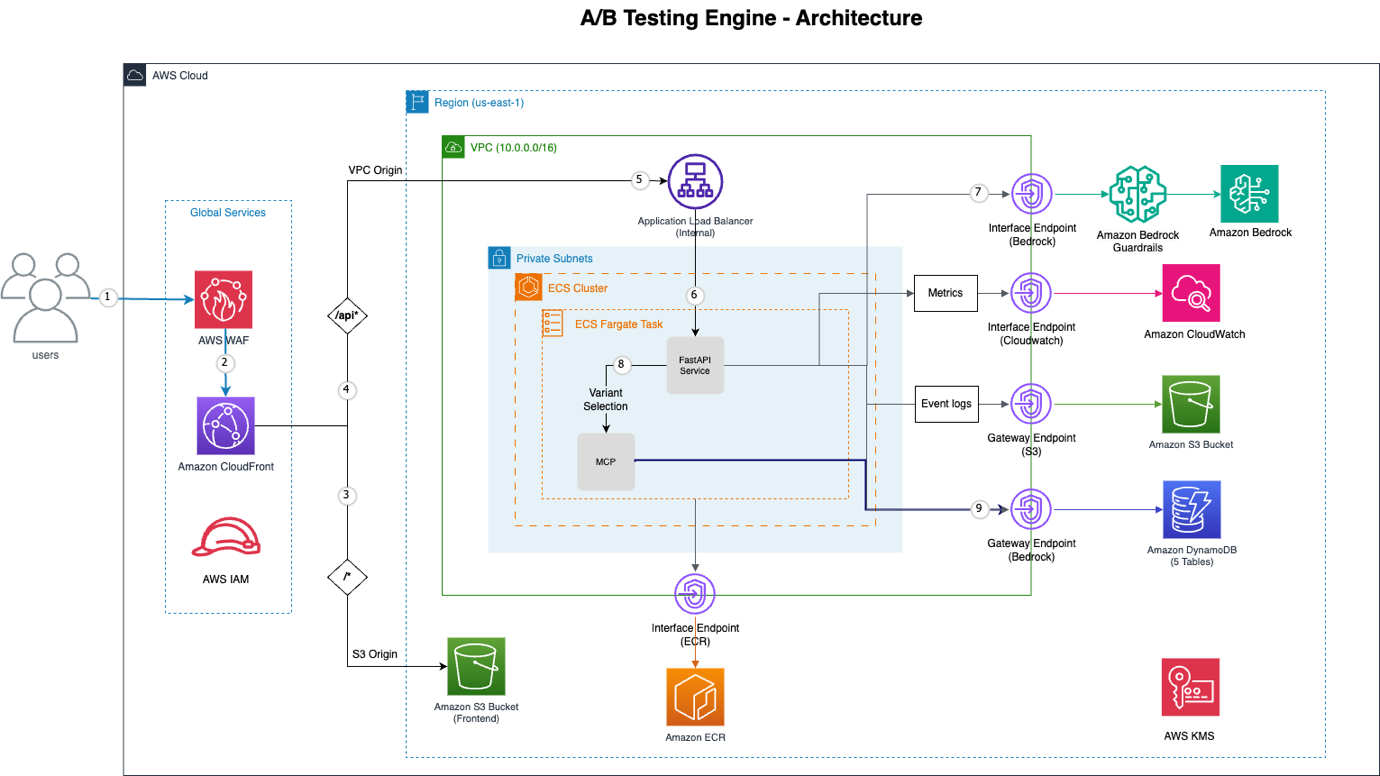
Фигура 1: Архитектура на механизма за A/B тестване
Ето разбивка на ключовите AWS компоненти, които правят това възможно:
| AWS услуга | Функционалност |
|---|---|
| Amazon CloudFront | Глобална мрежа за доставка на съдържание (CDN), осигуряваща защита от разпределен отказ на услуга (DDoS), предотвратяване на SQL инжекции и ограничаване на честотата. |
| AWS WAF | Уеб приложение защитна стена, интегрирана с CloudFront за подобрена сигурност. |
| VPC Origin | Установява частна връзка от Amazon CloudFront към вътрешен Application Load Balancer, елиминирайки излагането на публичен интернет за бек-енд услугите. |
| Amazon ECS с AWS Fargate | Безсървърна платформа за оркестрация на контейнери, изпълняваща приложението FastAPI, осигуряваща висока наличност и мащабируемост без управление на сървъри. |
| Amazon Bedrock | Централният двигател за AI решения, използващ модели като Claude Sonnet с вградено използване на инструменти за интелигентен избор на вариант. |
| Model Context Protocol (MCP) | Осигурява структуриран достъп до данни за поведението на потребителите и експерименти, позволявайки на Bedrock ефективно да извлича специфична информация. |
| VPC Endpoints | Осигурява частна свързаност към AWS услуги като Bedrock, DynamoDB, S3, ECR и CloudWatch, подобрявайки сигурността и намалявайки латентността. |
| Amazon DynamoDB | Напълно управлявана, безсървърна NoSQL база данни, предоставяща пет таблици за експерименти, събития, присвоявания, потребителски профили и пакетни задачи. |
| Amazon S3 | Използва се за хостинг на статичен фронтенд и трайно съхранение на регистрационни файлове на събития, предлагайки висока наличност и мащабируемост. |
Тази архитектура предоставя мощна и адаптивна платформа за експериментиране, позволяваща на организациите да надхвърлят ограниченията на произволното присвояване и да възприемат наистина интелигентен подход към A/B тестването.
Ролята на Amazon Bedrock в интелигентното присвояване на варианти
Истинската иновация на този механизъм за A/B тестване се крие в способността му да комбинира множество точки от данни – потребителски контекст, историческо поведение, модели от подобни потребители и показатели за ефективност в реално време – за да избере най-ефективния вариант. В основата на тази интелигентност е Amazon Bedrock, по-специално неговите възможности за разгръщане на усъвършенствани генеративни AI модели като Claude Sonnet с вградено използване на инструменти. Тази мощна комбинация позволява на системата да имитира експерт по A/B тестване, вземайки решения в реално време, базирани на данни, които се адаптират към индивидуалните взаимодействия на потребителите.
Когато потребител инициира заявка за вариант, системата не просто избира „А“ или „Б“. Вместо това, тя конструира изчерпателна подкана, която предоставя на Amazon Bedrock цялата необходима информация за вземане на информирано, оптимално решение. Този процес използва способността на Bedrock да интерпретира сложни инструкции и да използва предварително дефинирани инструменти за събиране на допълнителен контекст, като гарантира, че изкуственият интелект разполага с пълната картина, преди да препоръча присвояване. За по-задълбочено разбиране как се оценяват подобни интелигентни агенти в производство, разгледайте ресурси като Оценка на AI агенти за производство: Практическо ръководство за Strands' Evals.
Подканата за AI решение: Контекстуална интелигентност в действие
Ефективността на вземането на решения от Amazon Bedrock зависи от щателно изработената структура на подканата, която информира изкуствения интелект. Тази подкана се състои от две основни части: системна подкана, дефинираща ролята и поведението на Bedrock, и потребителска подкана, предоставяща специфични, контекстуални данни в реално време за решението. Този дизайн гарантира, че изкуственият интелект оперира в дефинирани граници, докато използва богата, динамична информация.
Ето концептуален поглед върху структурата на подканата, която Amazon Bedrock получава:
# Системна подкана (дефинира ролята и поведението на Amazon Bedrock)
system_prompt =
"""
Вие сте експерт специалист по оптимизация на A/B тестване с достъп до инструменти за събиране на данни за потребителско поведение.
КРИТИЧНИ ИНСТРУКЦИИ:
1. ВИНАГИ извиквайте get_user_assignment ПЪРВО, за да проверите за съществуващи присвоявания
2. Извиквайте други инструменти само ако имате нужда от специфична информация, за да вземете по-добро решение
3. Извиквайте инструменти въз основа на това каква информация би била ценна за това конкретно решение
4. Ако потребителят има съществуващо присвояване, запазете го, освен ако няма силни доказателства (30%+ подобрение) за промяна
5. КРИТИЧНО: Вашият окончателен отговор ТРЯБВА да бъде САМО валиден JSON без допълнителен текст, обяснения или коментари преди или след JSON обекта
Налични инструменти:
- get_user_assignment: Проверете съществуващо присвояване на вариант (ИЗВИКАЙТЕ ТОВА ПЪРВО)
- get_user_profile: Вземете поведенческия профил и предпочитанията на потребителя
- get_similar_users: Намерете потребители с подобни поведенчески модели
- get_experiment_context: Вземете конфигурация и ефективност на експеримента
- get_session_context: Анализирайте поведението на текущата сесия
- get_user_journey: Вземете историята на взаимодействията на потребителя
- get_variant_performance: Вземете показатели за ефективност на варианта
- analyze_user_behavior: Дълбочинен поведенчески анализ от историята на събитията
- update_user_profile: Актуализирайте потребителския профил с прозрения, извлечени от AI
- get_profile_learning_status: Проверете качеството на данните на профила и увереността
- batch_update_profiles: Пакетна актуализация на множество потребителски профили
Вземайте интелигентни, базирани на данни решения. Използвайте инструментите, от които се нуждаете, за да съберете достатъчно контекст за оптимален избор на вариант.
ФОРМАТ НА ОТГОВОРА: Върнете САМО JSON обекта. Не включвайте никакъв текст преди или след него."""
# Потребителска подкана (предоставя специфичен контекст за решението)
prompt = f"""Изберете оптималния вариант за този потребител в експеримент {experiment_id}.
ПОТРЕБИТЕЛСКИ КОНТЕКСТ:
- Потребителски ID: {user_context.user_id}
- ID на сесия: {user_context.session_id}
- Устройство: {user_context.device_type} (Мобилно: {bool(user_context.is_mobile)})
- Текуща страница: {user_context.current_session.current_page}
- Реферер: {user_context.current_session.referrer_type or 'direct'}
- Предишни варианти: {user_context.current_session.previous_variants or 'None'}
КОНТЕКСТУАЛНИ ПРОЗРЕНИЯ:
{analyze_user_context()}
КОНТЕКСТ ЗА ПЕРСОНАЛИЗАЦИЯ:
- Резултат за ангажираност: {profile.engagement_score:.2f}
- Вероятност за конверсия: {profile.conversion_likelihood:.2f}
- Стил на взаимодействие: {profile.interaction_style}
- Предишни успешни варианти: {
Тази изчерпателна подкана дава възможност на Amazon Bedrock да действа като интелигентен агент, вземайки нюансирани решения, вместо да разчита на груби произволни присвоявания. Чрез предоставяне на достъп до различни инструменти за извличане и анализ на данни, тя гарантира, че моделът разполага с цялата необходима информация за оптимизиране на индивидуалните потребителски предпочитания и целите на експеримента. Този подход значително подобрява прецизността и скоростта на A/B тестването, водейки до по-ефективни и персонализирани потребителски изживявания. Такова вградено използване на инструменти е мощна функция, подобна на концепции, изследвани в Amazon Bedrock AgentCore.
Отключване на мащабируемо и персонализирано експериментиране
Интегрирането на изкуствен интелект, по-специално чрез Amazon Bedrock, в методологиите за A/B тестване бележи ключова промяна от широки, рандомизирани експерименти към прецизни, адаптивни и персонализирани взаимодействия. Този двигател, задвижван от изкуствен интелект, не само смекчава ограниченията на традиционните подходи – като бавна конвергенция и висок шум – но също така въвежда несравними възможности за оптимизация в реално време. Чрез динамично присвояване на варианти въз основа на индивидуален потребителски контекст, поведенческа история и предсказуеми прозрения, организациите могат да постигнат по-бързи резултати, да извлекат по-задълбочена, приложима интелигентност и да предоставят наистина персонализирани потребителски изживявания.
Безсървърната архитектура, подкрепена от AWS услуги като Amazon ECS Fargate и Amazon DynamoDB, гарантира, че тази сложна система остава мащабируема и рентабилна, способна да обработва различни натоварвания без ръчна намеса. Този технологичен скок позволява на компаниите да надхвърлят простото идентифициране на „печеливш“ вариант за обща аудитория, към разбиране какво резонира най-добре с всеки уникален потребител във всеки даден момент. Бъдещето на оптимизацията на потребителското изживяване е безспорно адаптивно, интелигентно и задвижвано от изкуствен интелект, поставяйки нов стандарт за това как се развиват дигиталните продукти и услуги.
Оригинален източник
https://aws.amazon.com/blogs/machine-learning/build-an-ai-powered-a-b-testing-engine-using-amazon-bedrock/Често задавани въпроси
What are the primary limitations of traditional A/B testing methods?
How does an AI-powered A/B testing engine improve upon conventional A/B testing?
Which core AWS services are utilized to build this AI-powered A/B testing engine?
What role does Amazon Bedrock play in the intelligent variant assignment process?
What is the Model Context Protocol (MCP) and its significance in this architecture?
How does the AI decision prompt structure facilitate optimal variant selection?
What are the long-term benefits of implementing AI-powered A/B testing for organizations?
Бъдете информирани
Получавайте последните AI новини по имейл.