
Трудный путь GitHub: Оптимизация строк Diff для максимальной производительности
Запросы на слияние являются живым сердцем GitHub, где бесчисленное количество инженеров посвящают значительную часть своей профессиональной жизни. Учитывая огромные масштабы GitHub, обработка запросов на слияние, которые варьируются от незначительных исправлений одной строки до колоссальных изменений, охватывающих тысячи файлов и миллионы строк, процесс проверки должен оставаться исключительно быстрым и отзывчивым. Недавний запуск нового опыта на основе React для вкладки Измененные файлы, теперь являющейся стандартной для всех пользователей, стал ключевой инвестицией в обеспечение надежной производительности, особенно для этих сложных больших запросов на слияние. Это обязательство включало последовательное решение трудных проблем, таких как оптимизированный рендеринг, задержка взаимодействия и потребление памяти.
До этих оптимизаций, хотя большинство пользователей наслаждались отзывчивой работой, большие запросы на слияние неизбежно приводили к заметному снижению производительности. В экстремальных случаях куча JavaScript превышала 1 ГБ, количество узлов DOM превышало 400 000, а взаимодействия со страницей становились крайне медленными или даже непригодными для использования. Ключевые метрики отзывчивости, такие как Interaction to Next Paint (INP), взлетали выше приемлемых уровней, создавая ощутимое чувство задержки ввода для пользователей. Эта статья подробно описывает путь, который прошел GitHub, чтобы кардинально улучшить эти основные метрики производительности, преобразив опыт просмотра diff'ов.
Преодоление узких мест производительности: Многостратегический подход
При начале исследования производительности вкладки Измененные файлы быстро стало очевидно, что одного решения-«серебряной пули» будет недостаточно. Методы, разработанные для сохранения каждой функции и поведения, присущего браузеру, часто упирались в потолок при экстремальных нагрузках данных. И наоборот, меры, направленные исключительно на предотвращение наихудших сценариев, могли привести к неблагоприятным компромиссам для повседневных обзоров.
Вместо этого инженерная команда GitHub разработала комплексный набор стратегий, каждая из которых была тщательно продумана для решения проблем, связанных с конкретными размерами и сложностями запросов на слияние. Эти стратегии были построены на трех основных темах:
- Целевая оптимизация компонентов строк Diff: Повышение эффективности основного опыта работы с diff для большинства запросов на слияние. Это гарантировало, что средние и крупные обзоры оставались быстрыми без ущерба для ожидаемых функций, таких как встроенный поиск по странице.
- Плавная деградация с виртуализацией: Обеспечение удобства использования для самых больших запросов на слияние путем приоритета отзывчивости и стабильности, а также интеллектуального ограничения того, что отображается в любой момент времени.
- Инвестиции в базовые компоненты и улучшения рендеринга: Внедрение улучшений, которые приносят совокупные преимущества для всех размеров запросов на слияние, независимо от конкретного режима просмотра пользователя.
Эти стратегические столпы направляли усилия команды, позволяя им систематически устранять первопричины проблем с производительностью и готовить почву для последующих архитектурных доработок.
Деконструкция V1: Стоимость дорогой строки Diff
Первоначальная реализация GitHub на основе React, называемая v1, заложила основу для современного представления diff. Эта версия была искренней попыткой перенести классический вид Rails на React, отдавая приоритет созданию небольших, повторно используемых компонентов React и поддержанию четкой структуры дерева DOM. Однако этот подход, хоть и логичный на начальном этапе, оказался значительным узким местом при масштабировании.
В v1 рендеринг каждой строки diff был дорогостоящей операцией. Одна строка в объединенном представлении обычно преобразовывалась примерно в 10 элементов DOM, тогда как разделенное представление требовало около 15. Это количество еще больше увеличивалось при синтаксической подсветке, добавляя гораздо больше тегов <span>. На уровне React объединенные diff'ы содержали как минимум восемь компонентов на строку, а разделенные представления — минимум 13. Это были базовые значения, при этом дополнительные состояния пользовательского интерфейса, такие как комментарии, наведение и фокус, добавляли еще больше компонентов.
Архитектура v1 также страдала от распространения обработчиков событий React. Хотя на небольших масштабах это казалось безобидным, одна строка diff могла нести 20 или более обработчиков событий. При умножении на тысячи строк в большом запросе на слияние это быстро накапливалось, приводя к избыточным накладным расходам и увеличению использования кучи JavaScript. Эта сложность не только влияла на производительность, но и делала разработку и поддержку более трудоемкими. Первоначальный дизайн, эффективный для ограниченных данных, значительно затруднялся при столкновении с неограниченной природой разнообразных размеров запросов на слияние в GitHub.
Подводя итог, для каждой строки diff v1 система имела:
- Минимум 10-15 элементов дерева DOM
- Минимум 8-13 компонентов React
- Минимум 20 обработчиков событий React
- Множество мелких, повторно используемых компонентов React
Эта архитектура напрямую связывала большие размеры запросов на слияние с более медленным INP и увеличенным использованием кучи JavaScript, что потребовало фундаментальной переоценки и перепроектирования.
Революция в рендеринге: Влияние оптимизаций V2
Переход к v2 ознаменовал собой значительную архитектурную перестройку, сосредоточенную на детальных, значимых изменениях. Команда приняла философию, что «никакое изменение не является слишком малым, когда речь идет о производительности, особенно в масштабе». Ярким примером было удаление ненужных тегов <code> из ячеек номеров строк. Хотя удаление двух узлов DOM на строку diff может показаться незначительным, для 10 000 строк это мгновенно означало 20 000 меньше узлов в DOM, демонстрируя, как целенаправленные, инкрементальные оптимизации приносят существенные улучшения.
Визуальное сравнение ниже подчеркивает сниженную сложность от v1 до v2 на уровне компонентов:
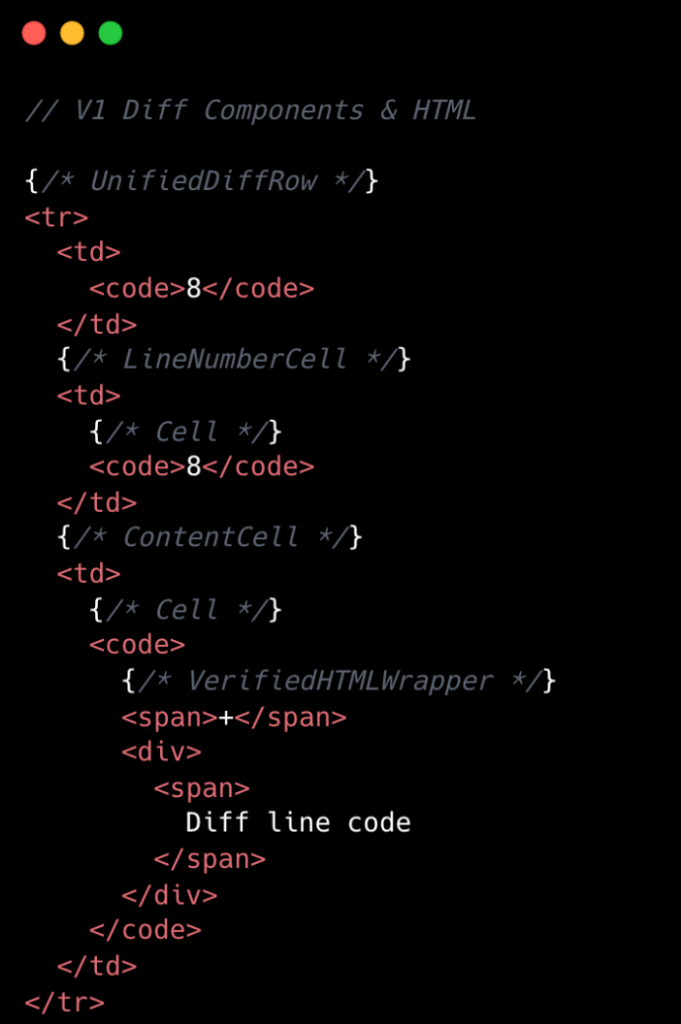
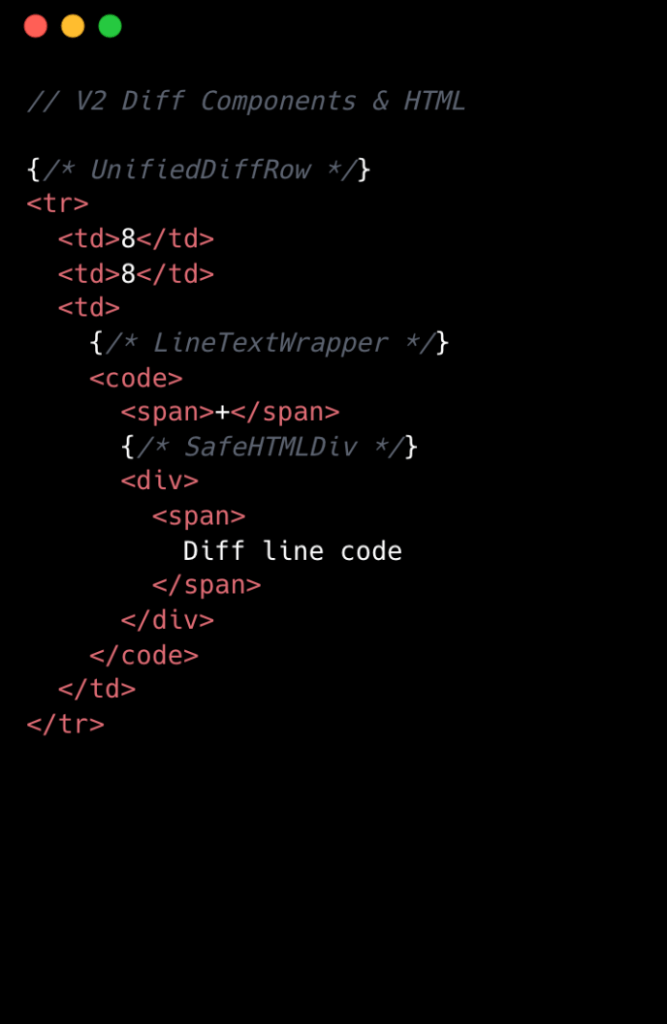
Оптимизированная архитектура компонентов
Ключевое нововведение в v2 заключалось в упрощении дерева компонентов. Команда сократила количество компонентов React на строку diff с восьми до двух. Это было достигнуто путем устранения глубоко вложенных деревьев компонентов и создания выделенных компонентов для каждой разделенной и объединенной строки diff. Хотя это привело к некоторому дублированию кода, оно значительно упростило доступ к данным и снизило общую сложность. Обработка событий также была централизована и теперь управлялась одним обработчиком верхнего уровня с использованием значений data-attribute, заменив многочисленные индивидуальные обработчики событий v1. Такой подход значительно оптимизировал как код, так и производительность.
Интеллектуальное управление состоянием и доступ к данным за O(1)
Возможно, наиболее значительным изменением стало перемещение сложного состояния приложения, такого как комментирование и контекстные меню, в условно отображаемые дочерние компоненты. В такой среде, как GitHub, где запросы на слияние могут превышать тысячи строк, неэффективно, чтобы каждая строка несла сложное состояние комментирования, когда лишь небольшая часть когда-либо будет иметь комментарии. Переместив это состояние во вложенные компоненты, основная ответственность компонента строки diff стала чисто рендерингом кода, что соответствует принципу единой ответственности.
Кроме того, v2 решила проблему поиска с временной сложностью O(n) и чрезмерного использования хуков useEffect, которые преследовали v1. Команда применила двухэтапную стратегию: строго ограничила использование useEffect верхним уровнем файлов diff и установила правила линтинга для предотвращения их повторного введения в компоненты обертывания строк. Это обеспечило точное мемоизирование и предсказуемое поведение. Одновременно, глобальные и diff-машины состояний были перепроектированы для использования поиска за O(1) постоянное время с помощью объектов JavaScript Map. Это позволило использовать быстрые, согласованные селекторы для таких общих операций, как выбор строки и управление комментариями, значительно повышая качество кода, улучшая производительность и снижая сложность за счет использования плоских, отображенных структур данных. Этот тщательный подход к оптимизации рабочих процессов разработчиков и базовой архитектуры обеспечивает надежную, масштабируемую систему.
Измеримое воздействие: V2 обеспечивает измеримые выгоды
Тщательные архитектурные и кодовые оптимизации, реализованные в v2, привели к глубоким, измеримым улучшениям по ключевым метрикам производительности. Новая система работает значительно быстрее, с массивным снижением использования кучи JavaScript и показателей INP. Следующая таблица демонстрирует драматические улучшения, наблюдаемые на репрезентативном запросе на слияние с 10 000 изменениями строк в режиме разделенного diff:
| Метрика | v1 | v2 | Улучшение |
|---|---|---|---|
| Куча JavaScript | 1ГБ+ | 250МБ | 75% |
| Узлы DOM | 400,000+ | 80,000 | 80% |
| INP p95 | 1000мс+ | 100мс | 90% |
Эти цифры подчеркивают успех многосторонней стратегии GitHub. Сокращение размера кучи JavaScript на 75% и уменьшение количества узлов DOM на 80% не только приводит к более легкому следу в браузере, но и напрямую способствует созданию более стабильного и отзывчивого интерфейса. Самое впечатляющее улучшение, снижение INP p95 (95-го процентиля задержки взаимодействия) на 90%, означает, что 95% взаимодействий пользователя теперь завершаются всего за 100 миллисекунд, практически устраняя задержку ввода, которая преследовала большие запросы на слияние в v1. Это значительно улучшает пользовательский опыт, делая большие обзоры кода такими же плавными и отзывчивыми, как и меньшие.
Приверженность GitHub непрерывному улучшению, подтвержденная этим глубоким анализом оптимизации строк diff, является свидетельством их стремления предоставить разработчикам платформу мирового класса. Путем тщательного анализа узких мест производительности и внедрения целенаправленных архитектурных решений они не только решили критические проблемы масштабируемости, но и установили новый стандарт отзывчивости в своем основном продукте. Этот акцент на производительность гарантирует, что инженеры могут эффективно выполнять важные задачи, такие как ревью кода, что в конечном итоге приводит к более высокому качеству и безопасности кода и более продуктивной среде разработки.
Первоисточник
https://github.blog/engineering/architecture-optimization/the-uphill-climb-of-making-diff-lines-performant/Часто задаваемые вопросы
What is the 'Files changed' tab in GitHub pull requests and why was its performance critical?
What were the primary performance challenges GitHub faced with large pull requests in the v1 architecture?
How did GitHub approach solving the complex performance issues, moving beyond a 'silver bullet' solution?
What were the key limitations of the 'v1' diff rendering architecture that made it unsustainable for scale?
What specific architectural changes were implemented in 'v2' to drastically improve diff line performance?
How did the GitHub engineering team achieve quantifiable improvements in JavaScript heap, DOM nodes, and INP metrics with v2?
What is Interaction to Next Paint (INP) and why is its improvement significant for GitHub's user experience?
Будьте в курсе
Получайте последние новости ИИ на почту.