
La difficile ascension de GitHub : optimiser les lignes de diff pour une performance optimale
Les pull requests constituent le cœur vibrant de GitHub, où d'innombrables ingénieurs consacrent une part significative de leur vie professionnelle. Étant donné l'immense échelle de GitHub, la gestion des pull requests, allant de corrections mineures d'une seule ligne à des changements colossaux s'étendant sur des milliers de fichiers et des millions de lignes, l'expérience de révision doit rester exceptionnellement rapide et réactive. Le déploiement récent de la nouvelle expérience basée sur React pour l'onglet Fichiers modifiés, désormais la valeur par défaut pour tous les utilisateurs, a marqué un investissement crucial pour garantir une performance robuste, en particulier pour ces grandes pull requests complexes. Cet engagement a impliqué de s'attaquer constamment à des problèmes difficiles tels que le rendu optimisé, la latence d'interaction et la consommation de mémoire.
Avant ces optimisations, bien que la plupart des utilisateurs bénéficiaient d'une expérience réactive, les grandes pull requests entraînaient inévitablement un déclin de performance notable. Dans les cas extrêmes, la mémoire JavaScript (heap) dépassait 1 Go, le nombre de nœuds DOM dépassait 400 000, et les interactions de page devenaient gravement lentes ou même inutilisables. Les métriques de réactivité clés comme l'Interaction to Next Paint (INP) s'envolaient au-dessus des niveaux acceptables, créant une sensation tangible de décalage d'entrée pour les utilisateurs. Cet article explore le parcours détaillé entrepris par GitHub pour améliorer considérablement ces métriques de performance fondamentales, transformant ainsi l'expérience de révision des diffs.
Naviguer les goulots d'étranglement de performance : une approche multi-stratégique
Lors du lancement de l'enquête sur la performance de l'onglet Fichiers modifiés, il est rapidement apparu qu'une solution "miracle" unique ne suffirait pas. Les techniques conçues pour préserver chaque fonctionnalité et comportement natif du navigateur atteignaient souvent un plafond avec des charges de données extrêmes. Inversement, les mesures d'atténuation visant uniquement à prévenir les scénarios les plus défavorables pouvaient introduire des compromis défavorables pour les révisions quotidiennes.
Au lieu de cela, l'équipe d'ingénierie de GitHub a développé un ensemble complet de stratégies, chacune méticuleusement conçue pour répondre à des tailles et des complexités spécifiques de pull requests. Ces stratégies ont été bâties sur trois thèmes principaux :
- Optimisations ciblées pour les composants de ligne de diff : Améliorer l'efficacité de l'expérience de diff principale pour la majorité des pull requests. Cela garantissait que les révisions moyennes et grandes restaient rapides sans compromettre les fonctionnalités attendues comme la recherche native dans la page.
- Dégradation progressive avec virtualisation : Assurer la convivialité pour les pull requests les plus volumineuses en priorisant la réactivité et la stabilité, et en limitant intelligemment ce qui est rendu à tout moment.
- Investissement dans les composants fondamentaux et les améliorations de rendu : Mettre en œuvre des améliorations qui génèrent des avantages cumulatifs pour toutes les tailles de pull requests, quel que soit le mode de visualisation spécifique de l'utilisateur.
Ces piliers stratégiques ont guidé les efforts de l'équipe, leur permettant de s'attaquer systématiquement aux causes profondes des problèmes de performance et de préparer le terrain pour les raffinements architecturaux ultérieurs.
Déconstruction de la V1 : le coût d'une ligne de diff coûteuse
L'implémentation initiale de GitHub basée sur React, appelée v1, a jeté les bases de la vue de diff moderne. Cette version était un effort sincère pour porter la vue Rails classique vers React, en priorisant la création de petits composants React réutilisables et le maintien d'une structure d'arbre DOM claire. Cependant, cette approche, bien que logique à ses débuts, s'est avérée être un goulot d'étranglement significatif à l'échelle.
Dans la v1, le rendu de chaque ligne de diff était une opération coûteuse. Une seule ligne dans une vue unifiée se traduisait généralement par environ 10 éléments DOM, tandis qu'une vue fractionnée en nécessitait près de 15. Ce nombre augmentait encore avec la coloration syntaxique, introduisant de nombreuses balises <span> supplémentaires. Au niveau de React, les diffs unifiés contenaient au moins huit composants par ligne, et les vues fractionnées un minimum de 13. Il s'agissait de comptes de base, avec des états d'interface utilisateur supplémentaires comme les commentaires, le survol et le focus, ajoutant encore plus de composants.
L'architecture v1 souffrait également d'une prolifération de gestionnaires d'événements React. Bien que cela semble inoffensif à petite échelle, une seule ligne de diff pouvait contenir 20 gestionnaires d'événements ou plus. Multiplié par des milliers de lignes dans une grande pull request, cela s'accumulait rapidement, entraînant une surcharge excessive et une utilisation accrue du tas JavaScript. Cette complexité n'a pas seulement eu un impact sur les performances, mais a également rendu le développement et la maintenance plus difficiles. La conception initiale, efficace pour des données bornées, a eu beaucoup de mal face à la nature illimitée des diverses tailles de pull requests de GitHub.
Pour résumer, pour chaque ligne de diff v1, le système avait :
- Minimum de 10 à 15 éléments d'arbre DOM
- Minimum de 8 à 13 composants React
- Minimum de 20 gestionnaires d'événements React
- De nombreux petits composants React réutilisables
Cette architecture corrélait directement les pull requests de plus grande taille avec un INP plus lent et une utilisation accrue du tas JavaScript, nécessitant une réévaluation et une refonte fondamentales.
Révolutionner le rendu : l'impact des optimisations de la V2
La transition vers la v2 a marqué une refonte architecturale significative, axée sur des changements granulaires et percutants. L'équipe a adopté la philosophie selon laquelle "aucun changement n'est trop petit en matière de performance, surtout à l'échelle". Un exemple frappant a été la suppression des balises <code> inutiles des cellules de numéro de ligne. Bien que la suppression de deux nœuds DOM par ligne de diff puisse sembler mineure, sur 10 000 lignes, cela équivalait instantanément à 20 000 nœuds de moins dans le DOM, démontrant comment des optimisations ciblées et incrémentales apportent des améliorations substantielles.
La comparaison visuelle ci-dessous met en évidence la réduction de complexité de la v1 à la v2 au niveau des composants :
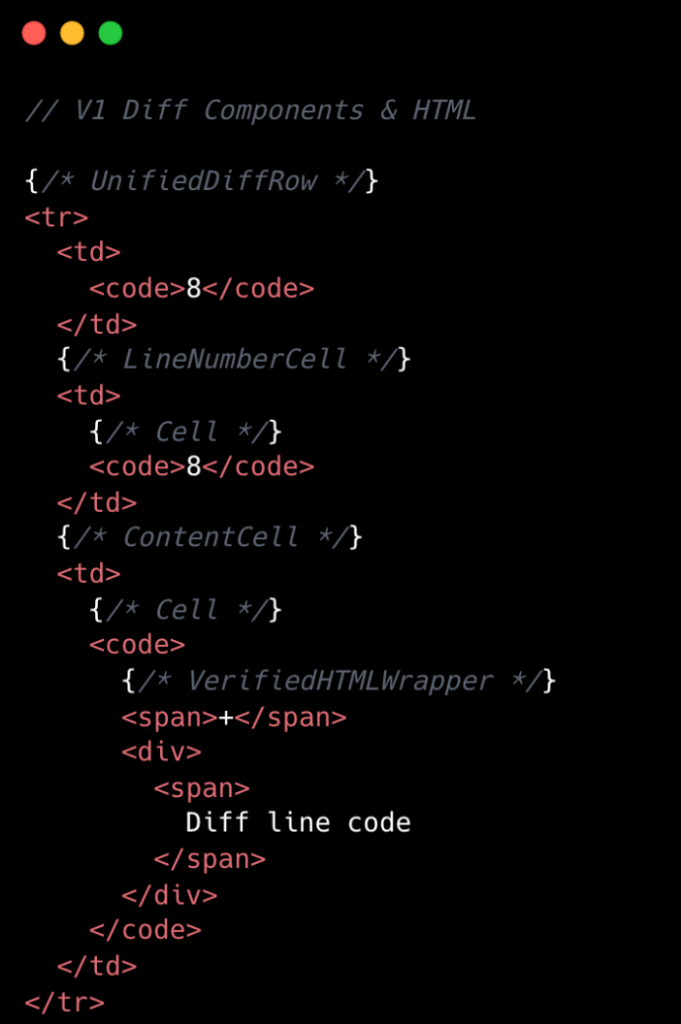
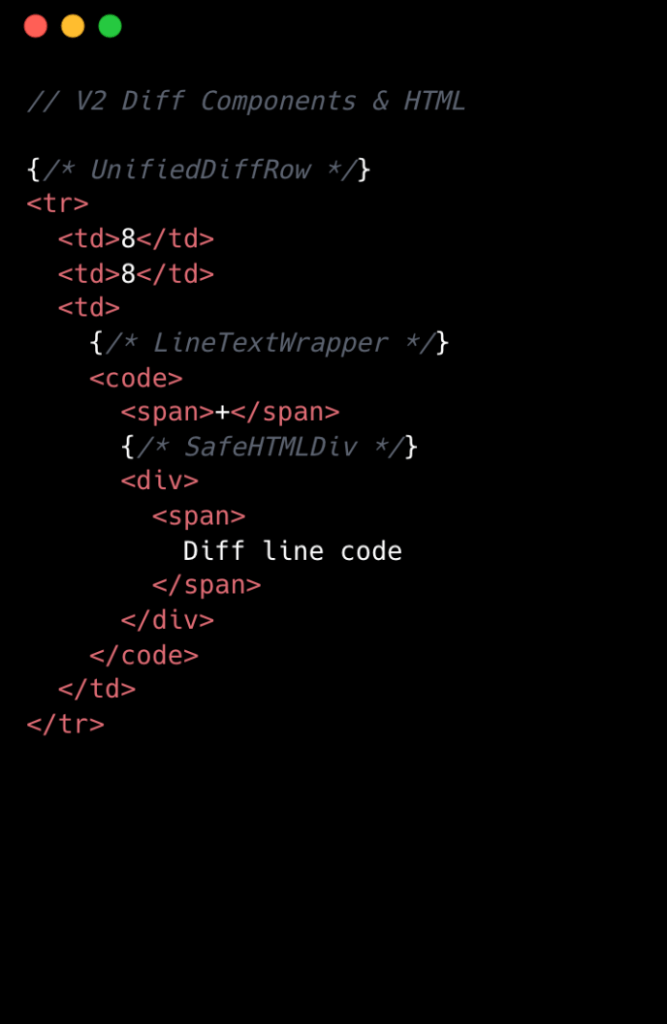
Architecture de composants rationalisée
Une innovation majeure de la v2 a été la simplification de l'arborescence des composants. L'équipe est passée de huit composants React par ligne de diff à deux. Cela a été réalisé en éliminant les arborescences de composants profondément imbriquées et en créant des composants dédiés pour chaque ligne de diff fractionnée et unifiée. Bien que cela ait introduit une certaine duplication de code, cela a drastiquement simplifié l'accès aux données et réduit la complexité globale. La gestion des événements a également été centralisée, désormais gérée par un seul gestionnaire de haut niveau utilisant des valeurs data-attribute, remplaçant les nombreux gestionnaires d'événements individuels de la v1. Cette approche a considérablement rationalisé le code et les performances.
Gestion intelligente de l'état et accès aux données en O(1)
Le changement le plus impactant a peut-être été la relocalisation de l'état complexe de l'application, comme les commentaires et les menus contextuels, dans des composants enfants rendus conditionnellement. Dans un environnement comme GitHub, où les pull requests peuvent dépasser des milliers de lignes, il est inefficace pour chaque ligne de transporter un état de commentaire complexe alors qu'une petite fraction seulement aura des commentaires. En déplaçant cet état dans des composants imbriqués, la responsabilité principale du composant de ligne de diff est devenue purement le rendu du code, s'alignant sur le principe de responsabilité unique.
De plus, la v2 a abordé le problème des recherches en O(n) et des hooks useEffect excessifs qui affligeaient la v1. L'équipe a adopté une stratégie en deux parties : restreindre strictement l'utilisation de useEffect au niveau supérieur des fichiers de diff et établir des règles de linting pour empêcher leur réintroduction dans les composants d'enveloppement de ligne. Cela a assuré une mémoïsation précise et un comportement prévisible. Simultanément, les machines d'état globales et de diff ont été repensées pour exploiter les recherches en temps constant O(1) en utilisant des objets Map JavaScript. Cela a permis des sélecteurs rapides et cohérents pour les opérations courantes comme la sélection de ligne et la gestion des commentaires, améliorant considérablement la qualité du code, les performances et réduisant la complexité en maintenant des structures de données aplaties et mappées. Cette approche méticuleuse de l'optimisation des workflows de développement et de l'architecture sous-jacente garantit un système robuste et évolutif.
L'impact mesurable : la V2 offre des gains quantifiables
Les optimisations architecturales et au niveau du code méticuleuses mises en œuvre dans la v2 ont produit des améliorations profondes et quantifiables sur les métriques de performance clés. Le nouveau système fonctionne significativement plus vite, avec une réduction massive de l'utilisation du tas JavaScript et des scores INP. Le tableau suivant présente les améliorations spectaculaires observées sur une pull request représentative avec 10 000 changements de ligne dans un paramètre de diff fractionné :
| Métrique | v1 | v2 | Amélioration |
|---|---|---|---|
| Tas JavaScript | 1 Go+ | 250 Mo | 75 % |
| Nœuds DOM | 400 000+ | 80 000 | 80 % |
| INP p95 | 1000 ms+ | 100 ms | 90 % |
Ces chiffres soulignent le succès de la stratégie multi-facettes de GitHub. Une réduction de 75 % de la taille du tas JavaScript et une diminution de 80 % des nœuds DOM ne se traduit pas seulement par une empreinte de navigateur plus légère, mais contribue également directement à une interface plus stable et réactive. L'amélioration la plus frappante, une réduction de 90 % de l'INP p95 (le 95e centile de la latence d'interaction), signifie que 95 % des interactions utilisateur sont désormais terminées en seulement 100 millisecondes, éliminant virtuellement le décalage d'entrée qui affligeait les grandes pull requests dans la v1. Cela améliore considérablement l'expérience utilisateur, rendant les grandes révisions de code aussi fluides et réactives que les plus petites.
L'engagement de GitHub envers l'amélioration continue, comme en témoigne cette exploration approfondie de l'optimisation des lignes de diff, est une preuve de leur dévouement à fournir une plateforme de développement de classe mondiale. En analysant rigoureusement les goulots d'étranglement de performance et en mettant en œuvre des solutions architecturales ciblées, ils ont non seulement résolu des problèmes critiques d'évolutivité, mais ont également établi une nouvelle norme de réactivité dans leur produit principal. Cette concentration sur les performances garantit que les ingénieurs peuvent s'engager efficacement dans des tâches cruciales comme les révisions de code, menant finalement à une qualité et sécurité du code accrues et à un environnement de développement plus productif.
Source originale
https://github.blog/engineering/architecture-optimization/the-uphill-climb-of-making-diff-lines-performant/Questions Fréquentes
What is the 'Files changed' tab in GitHub pull requests and why was its performance critical?
What were the primary performance challenges GitHub faced with large pull requests in the v1 architecture?
How did GitHub approach solving the complex performance issues, moving beyond a 'silver bullet' solution?
What were the key limitations of the 'v1' diff rendering architecture that made it unsustainable for scale?
What specific architectural changes were implemented in 'v2' to drastically improve diff line performance?
How did the GitHub engineering team achieve quantifiable improvements in JavaScript heap, DOM nodes, and INP metrics with v2?
What is Interaction to Next Paint (INP) and why is its improvement significant for GitHub's user experience?
Restez informé
Recevez les dernières actualités IA dans votre boîte mail.