
Wspinaczka GitHub na szczyt: Optymalizacja linii diff dla maksymalnej wydajności
Pull requesty stanowią tętniące życiem serce GitHub, gdzie niezliczona liczba inżynierów poświęca znaczną część swojego życia zawodowego. Biorąc pod uwagę ogromną skalę GitHub, obsługę pull requestów, które wahają się od drobnych poprawek w jednej linii do kolosalnych zmian obejmujących tysiące plików i miliony linii, doświadczenie przeglądu musi pozostać wyjątkowo szybkie i responsywne. Niedawne wprowadzenie nowego, opartego na React doświadczenia dla zakładki Zmienione pliki, teraz domyślnego dla wszystkich użytkowników, stanowiło kluczową inwestycję w zapewnienie solidnej wydajności, zwłaszcza dla tych wymagających dużych pull requestów. To zaangażowanie wiązało się z konsekwentnym rozwiązywaniem trudnych problemów, takich jak zoptymalizowane renderowanie, opóźnienia interakcji i zużycie pamięci.
Przed tymi optymalizacjami, choć większość użytkowników cieszyła się responsywnym doświadczeniem, duże pull requesty nieuchronnie prowadziły do zauważalnego spadku wydajności. W skrajnych przypadkach sterta JavaScript przekraczała 1 GB, liczba węzłów DOM przekraczała 400 000, a interakcje na stronie stawały się niezwykle powolne lub wręcz nieużyteczne. Kluczowe metryki responsywności, takie jak Interaction to Next Paint (INP), szybowały powyżej akceptowalnych poziomów, tworząc namacalne poczucie opóźnienia we wprowadzaniu danych dla użytkowników. Ten artykuł zagłębia się w szczegółową podróż, jaką GitHub podjął, aby drastycznie poprawić te kluczowe metryki wydajności, transformując doświadczenie przeglądu diffów.
Pokonywanie wąskich gardeł wydajności: Podejście wieloaspektowe
Kiedy rozpoczynano badanie wydajności zakładki Zmienione pliki, szybko stało się jasne, że pojedyncze rozwiązanie typu "srebrna kula" nie wystarczy. Techniki zaprojektowane do zachowania każdej funkcji i natywnego zachowania przeglądarki często napotykały na limit przy ekstremalnych obciążeniach danych. Z kolei środki zaradcze mające na celu wyłącznie zapobieganie najgorszym scenariuszom mogłyby wprowadzić niekorzystne kompromisy dla codziennych przeglądów.
Zamiast tego, zespół inżynierów GitHub opracował kompleksowy zestaw strategii, każdą skrupulatnie zaprojektowaną do rozwiązywania problemów z konkretnymi rozmiarami i złożonościami pull requestów. Strategie te opierały się na trzech głównych tematach:
- Ukierunkowane optymalizacje dla komponentów linii diff: Zwiększenie wydajności podstawowego doświadczenia diff dla większości pull requestów. Zapewniło to, że średnie i duże przeglądy pozostały szybkie, nie naruszając oczekiwanych funkcjonalności, takich jak natywne wyszukiwanie na stronie.
- Łagodne zmniejszanie funkcjonalności z wirtualizacją: Zapewnienie użyteczności dla największych pull requestów poprzez priorytetyzację responsywności i stabilności oraz inteligentne ograniczanie tego, co jest renderowane w danym momencie.
- Inwestycje w fundamentalne komponenty i ulepszenia renderowania: Wdrożenie ulepszeń, które przynoszą skumulowane korzyści we wszystkich rozmiarach pull requestów, niezależnie od konkretnego trybu przeglądania przez użytkownika.
Te strategiczne filary kierowały wysiłkami zespołu, pozwalając im systematycznie zajmować się głównymi przyczynami problemów z wydajnością i przygotować grunt pod późniejsze udoskonalenia architektoniczne.
Dekonstrukcja V1: Koszt kosztownej linii diff
Początkowa implementacja GitHub oparta na React, określana jako v1, położyła podwaliny pod nowoczesny widok diff. Ta wersja była szczerym wysiłkiem przeniesienia klasycznego widoku Rails do React, priorytetowo traktując tworzenie małych, wielokrotnego użytku komponentów React i utrzymanie przejrzystej struktury drzewa DOM. Jednak to podejście, choć logiczne w momencie powstania, okazało się znaczącym wąskim gardłem w skali.
W v1 renderowanie każdej linii diff było kosztowną operacją. Pojedyncza linia w widoku ujednoliconym zazwyczaj przekładała się na około 10 elementów DOM, podczas gdy widok podzielony wymagał bliżej 15. Ta liczba jeszcze bardziej rosła wraz z podświetlaniem składni, wprowadzając wiele dodatkowych tagów <span>. Na poziomie React, ujednolicone diffy zawierały co najmniej osiem komponentów na linię, a widoki podzielone minimum 13. Były to liczby bazowe, z dodatkowymi stanami interfejsu użytkownika, takimi jak komentarze, najechanie i fokus, dodającymi jeszcze więcej komponentów.
Architektura v1 cierpiała również z powodu namnożenia obsług zdarzeń React. Chociaż pozornie nieszkodliwe na małą skalę, pojedyncza linia diff mogła zawierać 20 lub więcej obsług zdarzeń. Pomnożone przez tysiące linii w dużym pull requeście, to szybko się kumulowało, prowadząc do nadmiernego narzutu i zwiększonego zużycia sterty JavaScript. Ta złożoność nie tylko wpływała na wydajność, ale także czyniła rozwój i konserwację trudniejszymi. Początkowy projekt, skuteczny dla danych o ograniczonej objętości, znacząco borykał się z nieograniczonym charakterem różnorodnych rozmiarów pull requestów GitHub.
Podsumowując, dla każdej linii diff w v1 system miał:
- Minimum 10-15 elementów drzewa DOM
- Minimum 8-13 komponentów React
- Minimum 20 obsług zdarzeń React
- Wiele małych, wielokrotnego użytku komponentów React
Ta architektura bezpośrednio korelowała większe rozmiary pull requestów z wolniejszym INP i zwiększonym zużyciem sterty JavaScript, wymagając fundamentalnej ponownej oceny i przeprojektowania.
Rewolucja w renderowaniu: Wpływ optymalizacji V2
Przejście na v2 oznaczało znaczącą przebudowę architektury, skupiającą się na granularnych, wpływowych zmianach. Zespół przyjął filozofię, że "żadna zmiana nie jest zbyt mała, jeśli chodzi o wydajność, zwłaszcza na dużą skalę". Doskonałym przykładem było usunięcie zbędnych tagów <code> z komórek numerów linii. Chociaż usunięcie dwóch węzłów DOM na linię diff może wydawać się drobne, to w przypadku 10 000 linii, natychmiast oznaczało 20 000 mniej węzłów w DOM, pokazując, jak ukierunkowane, inkrementalne optymalizacje przynoszą znaczne ulepszenia.
Poniższe porównanie wizualne podkreśla zredukowaną złożoność od v1 do v2 na poziomie komponentów:
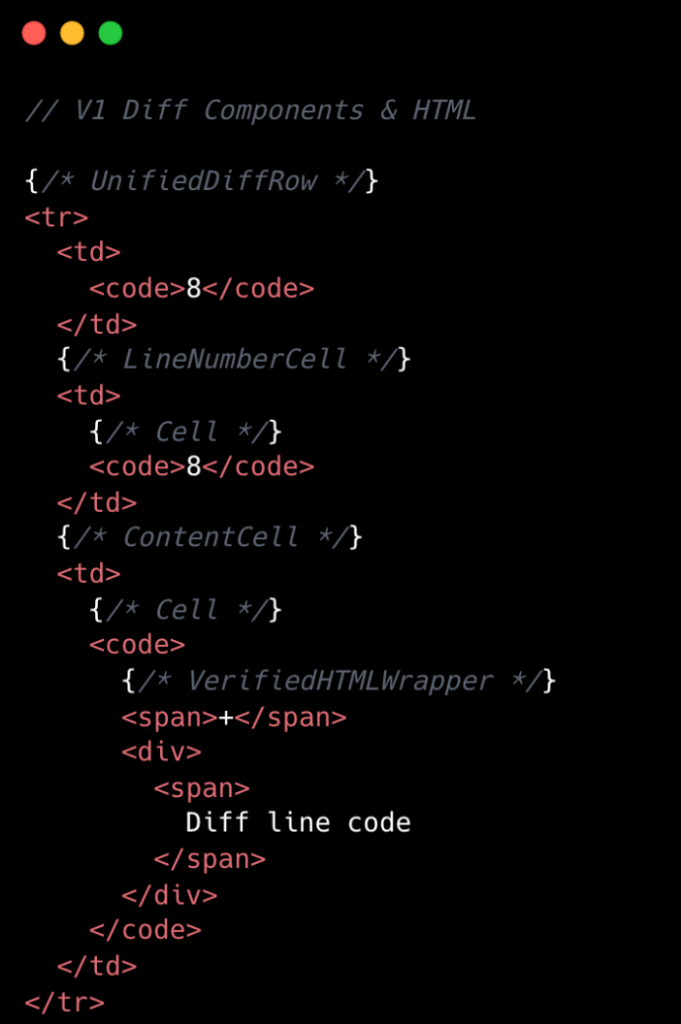
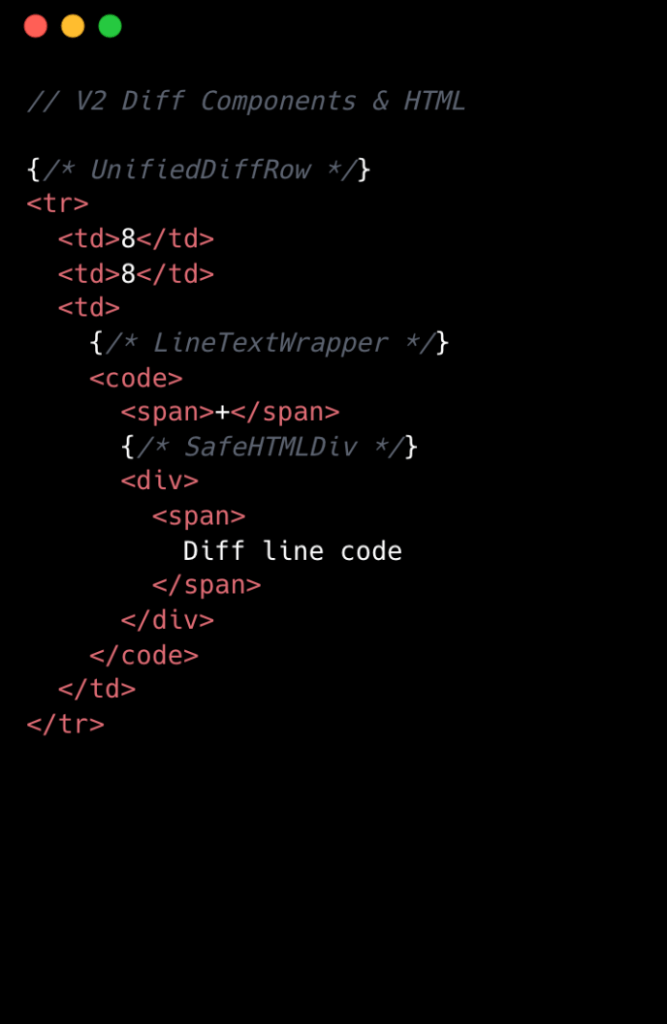
Usprawniona Architektura Komponentów
Kluczową innowacją w v2 było uproszczenie drzewa komponentów. Zespół przeszedł z ośmiu komponentów React na linię diff do dwóch. Osiągnięto to poprzez eliminację głęboko zagnieżdżonych drzew komponentów i tworzenie dedykowanych komponentów dla każdej podzielonej i ujednoliconej linii diff. Chociaż wprowadziło to pewne powielanie kodu, drastycznie uprościło dostęp do danych i zmniejszyło ogólną złożoność. Obsługa zdarzeń została również scentralizowana, teraz zarządzana przez pojedynczy handler najwyższego poziomu używający wartości data-attribute, zastępując liczne indywidualne handlery zdarzeń z v1. Takie podejście drastycznie usprawniło zarówno kod, jak i wydajność.
Inteligentne Zarządzanie Stanem i Dostęp do Danych O(1)
Być może najbardziej wpływowa zmiana polegała na przeniesieniu złożonego stanu aplikacji, takiego jak komentowanie i menu kontekstowe, do warunkowo renderowanych komponentów potomnych. W środowisku takim jak GitHub, gdzie pull requesty mogą przekraczać tysiące linii, jest nieefektywne, aby każda linia niosła ze sobą złożony stan komentowania, gdy tylko niewielka ich część kiedykolwiek będzie zawierać komentarze. Przenosząc ten stan do zagnieżdżonych komponentów, główna odpowiedzialność komponentu linii diff stała się wyłącznie renderowanie kodu, co jest zgodne z Zasadą Jednej Odpowiedzialności.
Ponadto, v2 rozwiązało problem wyszukiwań O(n) i nadmiernego użycia hooków useEffect, które nękały v1. Zespół przyjął dwuczęściową strategię: ścisłe ograniczenie użycia useEffect do najwyższego poziomu plików diff oraz ustanowienie zasad lintingu, aby zapobiec ich ponownemu wprowadzaniu w komponentach zawijających linie. Zapewniło to dokładną memoizację i przewidywalne zachowanie. Jednocześnie, globalne i diffowe maszyny stanów zostały przeprojektowane, aby wykorzystywać wyszukiwania w stałym czasie O(1) za pomocą obiektów JavaScript Map. Pozwoliło to na szybkie, spójne selektory dla typowych operacji, takich jak wybór linii i zarządzanie komentarzami, znacząco poprawiając jakość kodu, zwiększając wydajność i redukując złożoność poprzez utrzymywanie spłaszczonych, zmapowanych struktur danych. To skrupulatne podejście do optymalizacji przepływów pracy deweloperów i bazowej architektury zapewnia solidny, skalowalny system.
Mierzalny wpływ: V2 przynosi wymierne korzyści
Skrupulatne optymalizacje architektoniczne i na poziomie kodu wdrożone w v2 przyniosły głębokie, wymierne ulepszenia w kluczowych metrykach wydajności. Nowy system działa znacznie szybciej, z masową redukcją zużycia sterty JavaScript i wyników INP. Poniższa tabela przedstawia dramatyczne poprawy zaobserwowane na reprezentatywnym pull requeście z 10 000 zmianami linii w ustawieniu split diff:
| Metryka | v1 | v2 | Poprawa |
|---|---|---|---|
| Sterta JavaScript | 1GB+ | 250MB | 75% |
| Węzły DOM | 400,000+ | 80,000 | 80% |
| INP p95 | 1000ms+ | 100ms | 90% |
Dane te podkreślają sukces wieloaspektowej strategii GitHub. Redukcja rozmiaru sterty JavaScript o 75% i spadek liczby węzłów DOM o 80% nie tylko przekłada się na lżejszy ślad przeglądarki, ale także bezpośrednio przyczynia się do bardziej stabilnego i responsywnego interfejsu. Najbardziej uderzająca poprawa, 90% redukcja INP p95 (95. percentyla opóźnienia interakcji), oznacza, że 95% interakcji użytkownika jest teraz realizowanych w zaledwie 100 milisekund, praktycznie eliminując opóźnienie we wprowadzaniu danych, które nękało duże pull requesty w v1. To znacząco poprawia doświadczenie użytkownika, sprawiając, że duże przeglądy kodu są tak płynne i responsywne jak te mniejsze.
Zaangażowanie GitHub w ciągłe doskonalenie, czego dowodem jest to szczegółowe zagłębienie się w optymalizację linii diff, świadczy o ich poświęceniu w dostarczaniu światowej klasy platformy deweloperskiej. Poprzez rygorystyczną analizę wąskich gardeł wydajności i wdrażanie ukierunkowanych rozwiązań architektonicznych, nie tylko rozwiązali krytyczne problemy skalowalności, ale także ustanowili nowy standard responsywności w swoim głównym produkcie. Ten nacisk na wydajność zapewnia, że inżynierowie mogą efektywnie angażować się w kluczowe zadania, takie jak przeglądy kodu, co ostatecznie prowadzi do wyższej jakości i bezpieczeństwa kodu oraz bardziej produktywnego środowiska programistycznego.
Źródło oryginalne
https://github.blog/engineering/architecture-optimization/the-uphill-climb-of-making-diff-lines-performant/Często zadawane pytania
What is the 'Files changed' tab in GitHub pull requests and why was its performance critical?
What were the primary performance challenges GitHub faced with large pull requests in the v1 architecture?
How did GitHub approach solving the complex performance issues, moving beyond a 'silver bullet' solution?
What were the key limitations of the 'v1' diff rendering architecture that made it unsustainable for scale?
What specific architectural changes were implemented in 'v2' to drastically improve diff line performance?
How did the GitHub engineering team achieve quantifiable improvements in JavaScript heap, DOM nodes, and INP metrics with v2?
What is Interaction to Next Paint (INP) and why is its improvement significant for GitHub's user experience?
Bądź na bieżąco
Otrzymuj najnowsze wiadomości o AI na swoją skrzynkę.